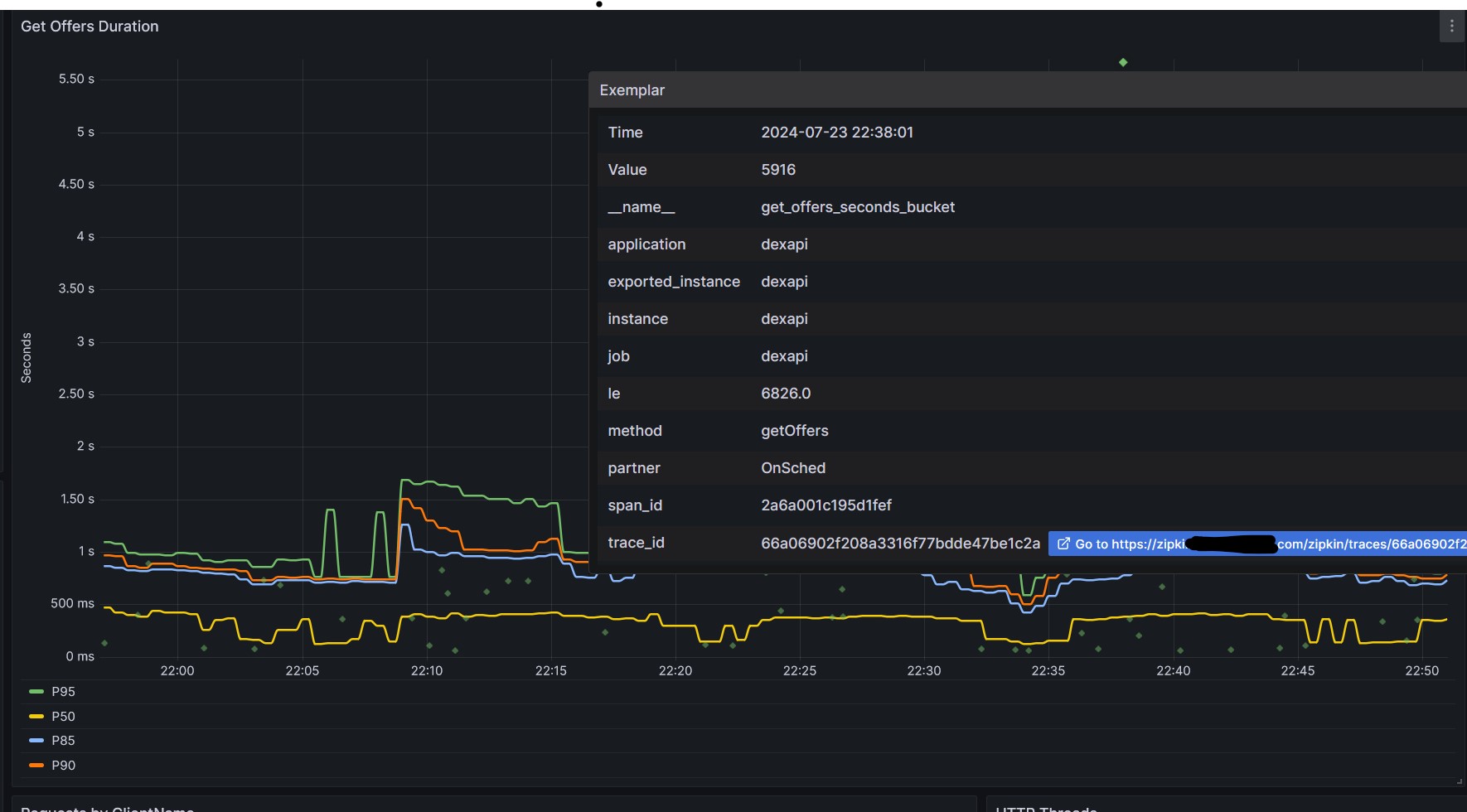
During a recent onboarding of a large customer, a series of microservices owned by my team experienced a massive spike in traffic. Our peak load skyrocketed from handling 60 requests per minute (RPM) to an eye-popping 6,000 RPM. This kind of growth is what engineers dream of—and dread—because scaling doesn’t come without its challenges.
The Architecture and the Problem
Our services are arranged in a chain:
- Internal Service A calls Internal Service B
- Internal Service B calls Internal Service C
- Internal Service C makes requests to various external services.
The external services, as one might expect, behaved unpredictably—sometimes responding quickly, sometimes with errors, timeouts, or long latencies. Essentially, the wild west of the internet.
On days when the downstream services were slow, we found ourselves consuming all available threads on the operating system (or in the container). This meant no more HTTP traffic could be served, effectively creating a cascading failure that took down critical parts of the system.
Digging into the Root Cause
Armed with tools like Prometheus, Zipkin, and old-fashioned logs, we zeroed in on the issue: we were running out of threads. But why?
The culprit turned out to be the traditional Java servlet model, which operates on a “one thread per request” basis. This model worked fine when traffic was manageable. But when downstream latencies increased and traffic surged by orders of magnitude, our system couldn’t keep up.
Why Not Just Scale Out?
Some might suggest scaling horizontally—adding more instances. In theory, this sounds simple. But in practice, it could have compounded our problems. Service C, the one interacting with downstream services, had scheduled tasks running every minute. These tasks weren’t coordinated, meaning every instance would independently run the same task, creating redundancy and additional load.
Eventually, we implemented solutions like:
- Scaling the services.
- Introducing leader election for scheduled tasks to avoid redundant executions.
- Improving resiliency with circuit breakers and timeouts for downstream calls.
But there was one more avenue we wanted to explore: Java 21.
Enter Java 21: Loom and Structured Concurrency
Java 21 brought significant innovations, particularly Project Loom and Structured Concurrency, which promised to reshape how Java applications handle concurrency.
- Virtual Threads (Project Loom):
Virtual threads are a game-changer for high-concurrency applications. Unlike traditional threads, they are lightweight and don’t block OS resources when waiting on I/O. This means we could maintain the simplicity of the “thread-per-request” model without the cost of running out of threads.By rewriting key parts of our applications to leverage virtual threads, we saw an immediate reduction in thread contention and an increase in throughput. Requests no longer stalled just because downstream services were slow or unresponsive. - Structured Concurrency:
Structured concurrency gave us better control over tasks running in parallel. Instead of ad hoc thread management, we could group related tasks and handle their lifecycle more predictably. This was particularly useful for service C, which needed to manage multiple downstream calls in a way that was both efficient and fault-tolerant.
The Results
The transition wasn’t without its challenges. Moving to Java 21 required some code refactoring and testing to ensure compatibility. But the payoff was enormous:
- Improved scalability: Virtual threads allowed us to handle the surge in requests without running out of system resources.
- Reduced latencies: The system became more responsive, even under heavy load.
- Simplified code: Structured concurrency made our task management more readable and maintainable.
Lessons Learned
- Measure Before You Scale: Tools like Prometheus and Zipkin were critical in diagnosing the problem. Without them, we might have thrown hardware at the problem without understanding the root cause.
- Embrace New Paradigms Carefully: Java 21’s features were a leap forward but required careful adoption. We didn’t just flip a switch; we analyzed, tested, and then implemented.
- Build for Resilience: Slow or failing downstream services are inevitable. By using patterns like circuit breakers, retries, and timeouts, we insulated the system from cascading failures.
Closing Thoughts
Scaling is never just about adding more servers; it’s about understanding the bottlenecks in your system and addressing them thoughtfully. Java 21 provided us with powerful tools to meet our scaling challenges head-on. If you’re managing high-concurrency applications, it might be time to take a hard look at what it can offer.
Leave a Reply