I’ve made some progress on my initial plan to use natural language processing to determine the narrator in text. This is only really useful if the narrative is third-person limited.
I found that the problem domain is not really well defined, and that the solutions that do exist are imperfect. This is, no doubt, my brutal introduction to NLP. I’ve heard of the topic before, but never really thought about how difficult it was until I started trying to use it, and thinking about approaches.
Libraries
I’m writing this in Java, so I have a few choices. Some of the most popular are:
Ultimately I went with CoreNLP as it has excellent documentation and is well regarded. It may not be fastest, but this isn’t code running 24/7 on large datasets.
Trial By Fire
So, I’m really a pedestrian when it comes to NLP, but I’m beginning to understand some of the distinct problems within it. There are quite a few (part-of-speech tagging, named entity resolution (NER) being among the most well known), and you can find out more about them here.
Approach: Coreference Resolution
For my application I think coreference resolution will be most helpful. Coreference resolution is when you are able to associate “He” with “Bob” in the following text.
“Bob is never on time. He is very inconsiderate.”
The reason I think this will be so helpful is that sections of text that are written with a certain perspective will have a high likelihood of containing a lot of references to that character.
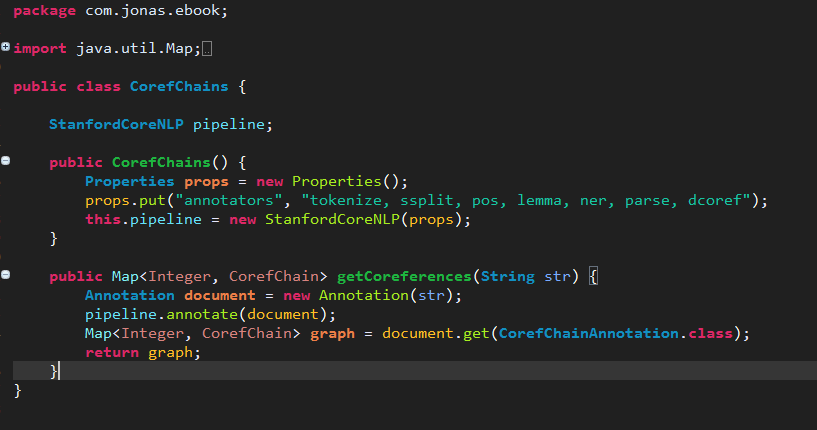
Code
Below is the code I am using to handle the text and create a model of coreferences.

The CorefChain Data Object
Here you can see what the data structure of the graph returned looks like in Eclipse’s debugger (as well as the beginning of the text it parsed):

Here is the map of mentions that “She Who Remembers” (the POV character for the prologue) got associated with:

And for completeness’s sake, here is the first paragraph:
On the day that she had hatched, she had been captured before she could wriggle over the sand to the cool and salty embrace of the sea. She Who Remembers was doomed to recall every detail of that day with clarity. It was her entire function and the reason for her existence. She was a vessel for memories. Not just her own life, from the moment when she began forming in the egg, but the linked lives of those who had gone before her were nested inside her. From egg to serpent to cocoon to dragon to egg, all memory of her line was hers. Not every serpent was so gifted, or so burdened. Only a relative few were imprinted with the full record of their species, but only a few were needed.
Approach
But my approach needs work. Here are the first five chapters processed with frequency counts vs my coreference resolution strategy (correct identifications are in bold):
Frequency Counts:
Prologue: [She Who Remembers]
1: [Malta, Keffria, Reyn]
2: [Ronica, Serilla]
3: [Kennit, Kennit, Wintrow, Kennit, Wintrow, Althea]
4: [Tintaglia, Reyn]
5: [Althea]
Coreference Resolution:
Prologue: [She Who Remembers]
Chapter 1: [The Satrap, Jani, Some]
Chapter 2: [Ronica Vestrit, Davad Restart]
Chapter 3: [Captain Kennit, Wintrow, Wintrow, Wintrow, Ah, No]
Chapter 4: [Beautiful, Reyn Khuprus]
Chapter 5: [Althea]
Frequency Counts are 100% correct, whereas the accuracy on the NLP side is more like 50%.
The attractive part of the NLP approach (besides being forced to learn some NLP) is that I don’t have to seed the program with the enumeration of character choices, it will do that on its own.
One thing I neglected to mention is the speed. Each chapter takes about 30 seconds on a relatively high-end desktop. Over the next week or two, I will refine my approach, and see if I can do better on the accuracy and performance aspects. Something I’d like to avoid, though, is coding for one case at the expense of all others. I’ll probably randomize the chapters used in testing.
Leave a Reply